Lectures
You can download the lectures here. We will try to upload lectures prior to their corresponding classes.
-

-
-
-
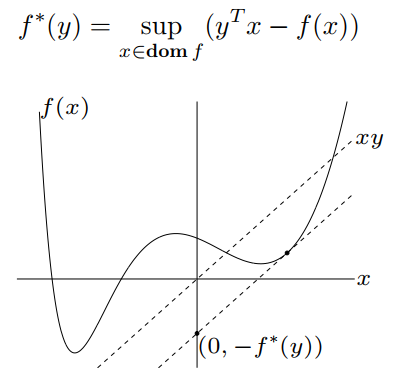
Lecture 9 Interior Point Method for Nonlinear Programming
tl;dr: Interior Point Method, Nonlinear Programmin
[notes]
Suggested Readings:
-
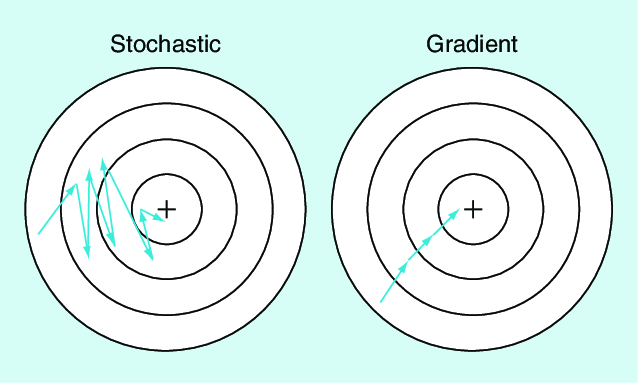 Lecture 10 Stochastic Gradient Descent I
Lecture 10 Stochastic Gradient Descent I
tl;dr: Stochastic Gradient Descent
[notes]
Suggested Readings:
Section 8.7.1, 8.7.2, and 8.7.3 of Liu et al.
-
Lecture 11 Stochastic Gradient Descent II
tl;dr: Stochastic Gradient Descent
[notes]
Suggested Readings:
Section 8.7.1, 8.7.2, and 8.7.3 of Liu et al.
-
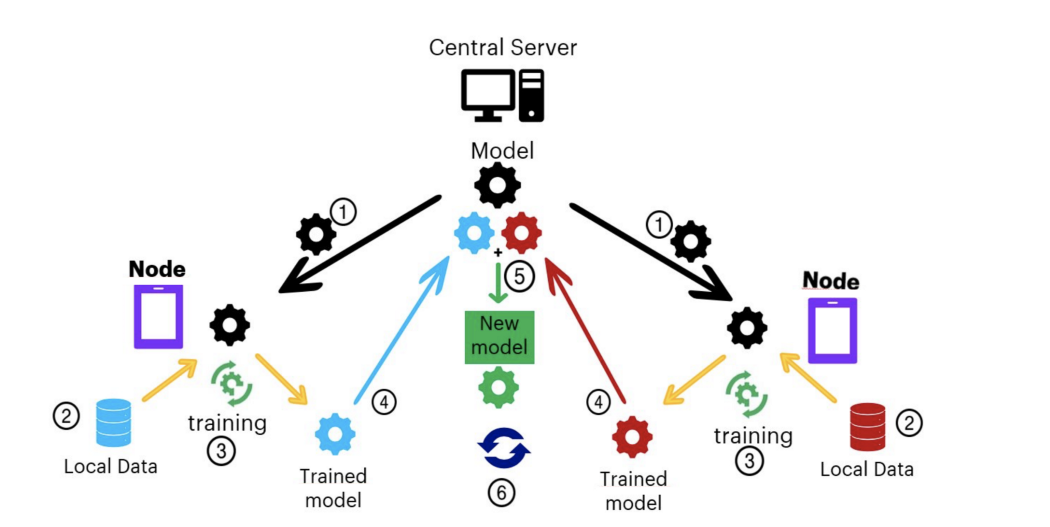 Lecture 12 Federated Optimization
Lecture 12 Federated Optimization
tl;dr: Federated Learning and Federated Optimization
[notes]
Suggested Readings:
Li, Xiang, Kaixuan Huang, Wenhao Yang, Shusen Wang, and Zhihua Zhang. “On the Convergence of FedAvg on Non-IID Data.” In International Conference on Learning Representations. 2019.
Kairouz, Peter, H. Brendan McMahan, Brendan Avent, Aurélien Bellet, Mehdi Bennis, Arjun Nitin Bhagoji, Kallista Bonawitz et al. “Advances and open problems in federated learning.” arXiv preprint arXiv:1912.04977 (2019).
-
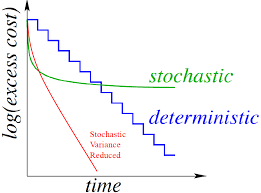 Lecture 13 Stochastic Variance Reduced Gradient and Block Coordinate Descent
Lecture 13 Stochastic Variance Reduced Gradient and Block Coordinate Descent
tl;dr: SVRG and BCD
[notes]
Suggested Readings:
Johnson, Rie, and Tong Zhang. “Accelerating stochastic gradient descent using predictive variance reduction.” Advances in neural information processing systems 26 (2013): 315-323.
Wright, Stephen J. “Coordinate descent algorithms.” Mathematical Programming 151, no. 1 (2015): 3-34.
-
 Lecture 14 Alternating Deirection Method of Multipliers
Lecture 14 Alternating Deirection Method of Multipliers
tl;dr: ADMM
[notes]
Suggested Readings:
Boyd, Stephen, Neal Parikh, Eric Chu, Borja Peleato, and Jonathan Eckstein. “Distributed optimization and statistical learning via the alternating direction method of multipliers.” Foundations and Trends in Machine Learning 3, no. 1 (2010): 1-122.
-
Lecture 15 Course Review
tl;dr: Review